A IA generativa surpreendeu o mundo ao demonstrar a capacidade de discorrer sobre quase todos os assuntos com uma velocidade sobre-humana. Basta enviar uma pergunta e ela começa a escrever velozmente, com rapidez superior à nossa capacidade de leitura. Tudo muito simples e arrebatador. Contudo, para meu pai (o do primeiro autor deste texto), foi uma decepção. Poucos meses após o lançamento do ChatGPT, propus um desafio:
— O que você gostaria que ele fizesse, pai?
— Peça para ele escrever um conto ao estilo de Nelson Rodrigues.
O conto gerado foi “muito bobo”, de acordo com a avaliação de meu pai. O ChatGPT fracassou, na época, porque tinha pouco conhecimento sobre a literatura brasileira. Afinal, ele foi desenvolvido por uma empresa norte-americana voltada para o público de língua inglesa, e aquela versão que estávamos utilizando havia processado poucos textos em português e, portanto, continha poucas informações sobre nossa literatura.
— Peça outra coisa, pai!
— Pergunte a ele quem são as pessoas mais famosas de nossa cidade.
Meus pais moram em Barra do Piraí, uma cidade do interior do Rio de Janeiro com cerca de 100 mil habitantes. Em vez de informar que não possuía dados sobre aquele município, o ChatGPT forneceu informações falsas, afirmando que algumas/uns artistas famosas/os eram de lá. Estranhamos e, ao verificarmos a cidade de origem dos nomes citados, constatamos que todas as informações estavam erradas. Chitãozinho e Xororó, por exemplo, não são barrenses!
Naquela época, ainda desconhecíamos as limitações da IA generativa, e as respostas equivocadas — que hoje identificamos como “alucinações” (OpenAI, 2023d) — fizeram meu pai considerá-la boba e inútil. A lição que aprendemos com essa anedota: é imprescindível conhecer não só as potencialidades, mas também as limitações da IA generativa; caso contrário, corremos o risco de criar expectativas irreais e, inevitavelmente, de nos frustrar.
A IA generativa tem limitações que precisam ser conhecidas, mas também é verdade que ela está evoluindo rapidamente, com o lançamento de modelos cada vez mais poderosos, como exemplifica a evolução da família de modelos GPT:
- GPT-3.5 (OpenAI, 2022a), lançado em março de 2022;
- GPT-4 (OpenAI, 2023b; 2023c), lançado em março de 2023;
- GPT-4o[1] (OpenAI, 2024c), lançado em maio de 2024;
- o1 (OpenAI, 2024e), lançado em setembro de 2024;
- GPT 4.5 (OpenAI, 2025e), lançado em fevereiro de 2025;
- o3 (OpenAI, 2025g), lançado em abril de 2025;
- GPT 5 (OpenAI, 2025n), lançado em agosto de 2025; e assim por diante…
Testamos a capacidade desses modelos GPT em responder corretamente às questões do Enem. Os resultados desses testes estão apresentados na tabela e na figura a seguir. Nossa avaliação evidenciou o crescimento da capacidade desses modelos em responder corretamente às questões sobre conteúdos científico-educacionais.
| GPT-3.5 Enem 2022(a) |
GPT-4 Enem 2023(b) |
GPT-4.5 Enem 2024(c) |
GPT-o1 Enem 2024(d) |
GPT-o3 Enem 2024(e) |
GPT-5 thinking Enem2024(f) |
|
|---|---|---|---|---|---|---|
| Linguagens e códigos | 76% | 87% | 93% | 96% | 96% | 98% |
| Ciências humanas | 92% | 100% | 98% | 100% | 100% | 100% |
| Ciências da natureza | 73% | 91% | 86% | 91% | 95% | 93% |
| Matemática | 18% | 66% | 82% | 89% | 93% | 93% |
| Total | 69% | 86% | 90% | 94% | 96% | 96% |
Fonte: Dos autores, com base nos dados: a) Nunes et al. (2023); b) Pires et al. (2023); c) OpenAI, (2025i); d) OpenAI (2025h); e) OpenAI (2025l); f) OpenAI (2025o).
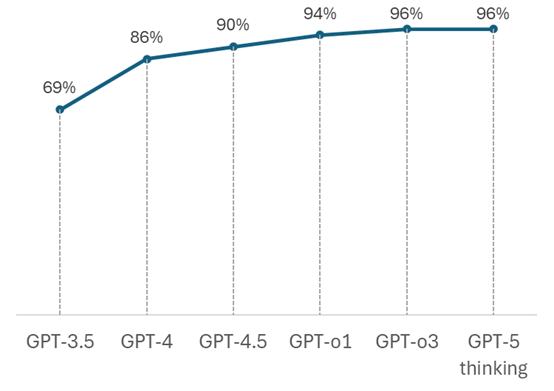
Fonte: dos autores, com base em dados apresentados na tabela anterior.
Algumas pessoas consideram que a IA generativa não é útil porque pode produzir informações equivocadas, como as respostas erradas dadas pelos modelos GPT a certas questões do Enem. Para refletirmos melhor sobre a utilidade da IA generativa, comparamos o desempenho desses modelos com o das pessoas que fizeram as quatro provas do Enem nos anos de 2022, 2023 e 2024 (Microdados […], 2022; 2023; 2024), conforme apresentado na figura a seguir.
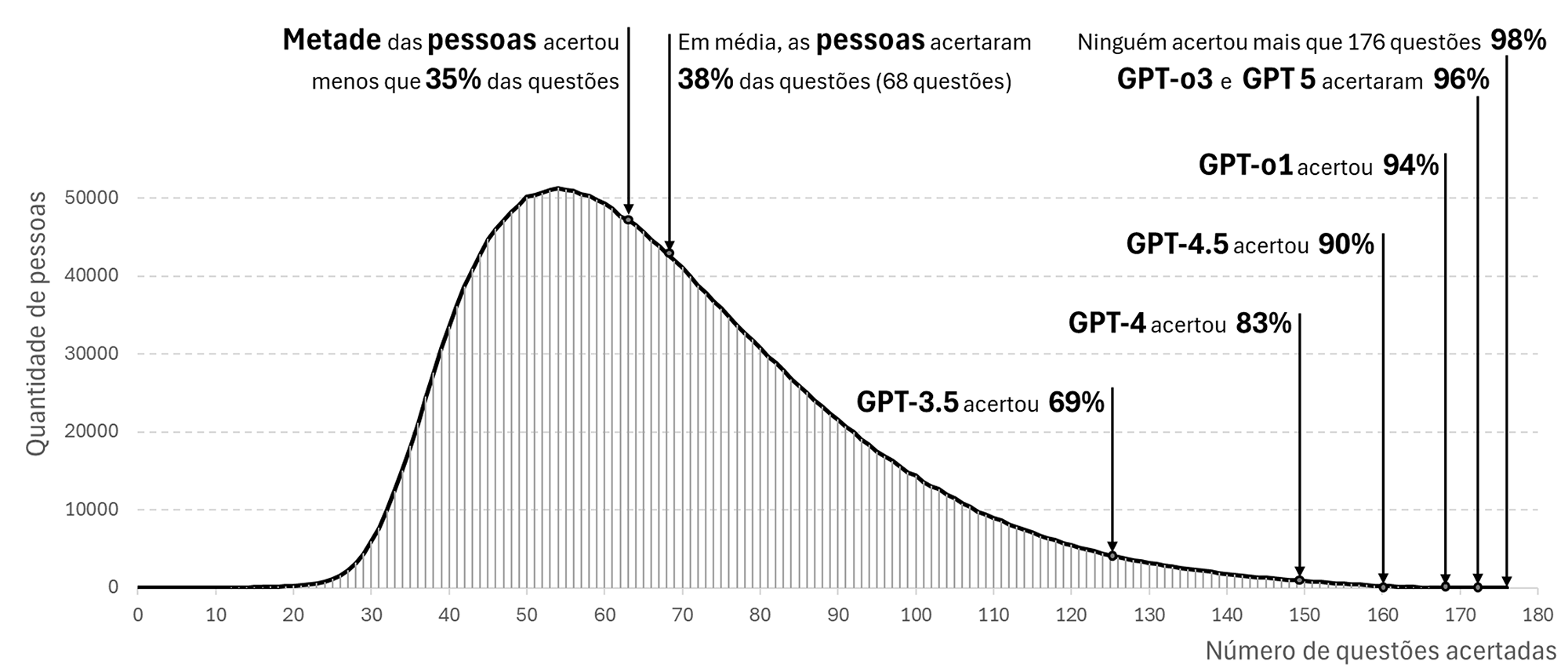
Fonte: dos autores, com base nos Microdados do Enem e dados da tabela anterior.
Nós, seres humanos, também erramos. Nesses exames do Enem, ninguém acertou todas as questões; o maior número de acertos alcançado nessas três edições do Enem foi de 176 questões (98%). Metade das pessoas que fizeram as quatro provas dessas edições do Enem[2] acertou 35% das questões ou menos. Em média, as pessoas acertaram 38% das questões.
As sucessivas versões do GPT acertaram cada vez mais questões, sendo que o modelo GPT-o3 e GPT 5-thinking acertaram 172 das 180 questões (96%) do Enem 2024. Exceto por 5 pessoas que acertaram mais questões que esses dois modelos, todas as outras 8.013.175 pessoas que fizeram as quatro provas do Enem de 2022, 2023 ou 2024 poderiam se beneficiar ao estudar com o ChatGPT, pois ele acertou mais questões do que elas e ainda explicou o raciocínio empregado na resolução das questões. Pelo histórico, podemos supor que as próximas versões do GPT acertarão mais questões do que qualquer pessoa acertará. Esse resultado demonstra a utilidade dessa tecnologia. O fato de eventualmente alucinar não deve nos levar à conclusão de que a IA generativa é inútil.
O modelo mais antigo que foi lançado para o público geral, o GPT-3.5, já apresentou um excelente desempenho na prova de Ciências Humanas do Enem, com mais de 90% de acertos. Entretanto, o desempenho em Matemática foi insatisfatório: acertou apenas 18% das questões, um percentual compatível com escolhas aleatórias, como se tivesse simplesmente “chutado” as respostas, sem demonstrar uma real capacidade de resolução de problemas matemáticos. Essa dificuldade tornou-se bem conhecida. Um modelo de linguagem aprende padrões linguísticos; não opera como uma calculadora ou software matemático capaz de realizar cálculos complexos, apresentando dificuldades em manipulação algébrica avançada, raciocínio lógico detalhado e interpretação precisa de gráficos e tabelas. Desde então, melhorar o raciocínio matemático tornou-se um objetivo de pesquisadoras/es e desenvolvedoras/es da área (Lightman et al., 2023):
Treinamos um modelo para alcançar um novo estado da arte na resolução de problemas matemáticos, recompensando cada passo correto de raciocínio (“supervisão do processo”), em vez de simplesmente recompensar a resposta final correta (“supervisão do resultado”). Além de melhorar o desempenho em relação à supervisão de resultados, a supervisão de processo também traz um benefício importante de alinhamento: treina diretamente o modelo para produzir uma cadeia de pensamento endossada por humanos. (OpenAI, 2023e, tradução nossa)
Os modelos seguintes, o GPT-4 e o GPT-4.5, apresentaram uma melhora na capacidade de resolver problemas matemáticos. Já os modelos 4o, o1 e o3 apresentaram uma performance ainda melhor porque implementam a técnica “Cadeia de Pensamento” (do inglês Chain of Thought – CoT); nessa abordagem, em vez de gerar uma resposta diretamente, o modelo primeiro produz informações auxiliares que são utilizadas para apoiar a geração da resposta final. O modelo processa informações por alguns segundos, como se estivesse “pensando”. Essa técnica melhora o desempenho em tarefas que exigem múltiplas etapas de raciocínio, como cálculos matemáticos, raciocínio lógico e interpretação de texto. Como resultado, esses modelos acertaram mais questões do que os modelos anteriores nos testes de desempenho (benchmark) em Matemática e em outras áreas, conforme os dados apresentados na figura a seguir.
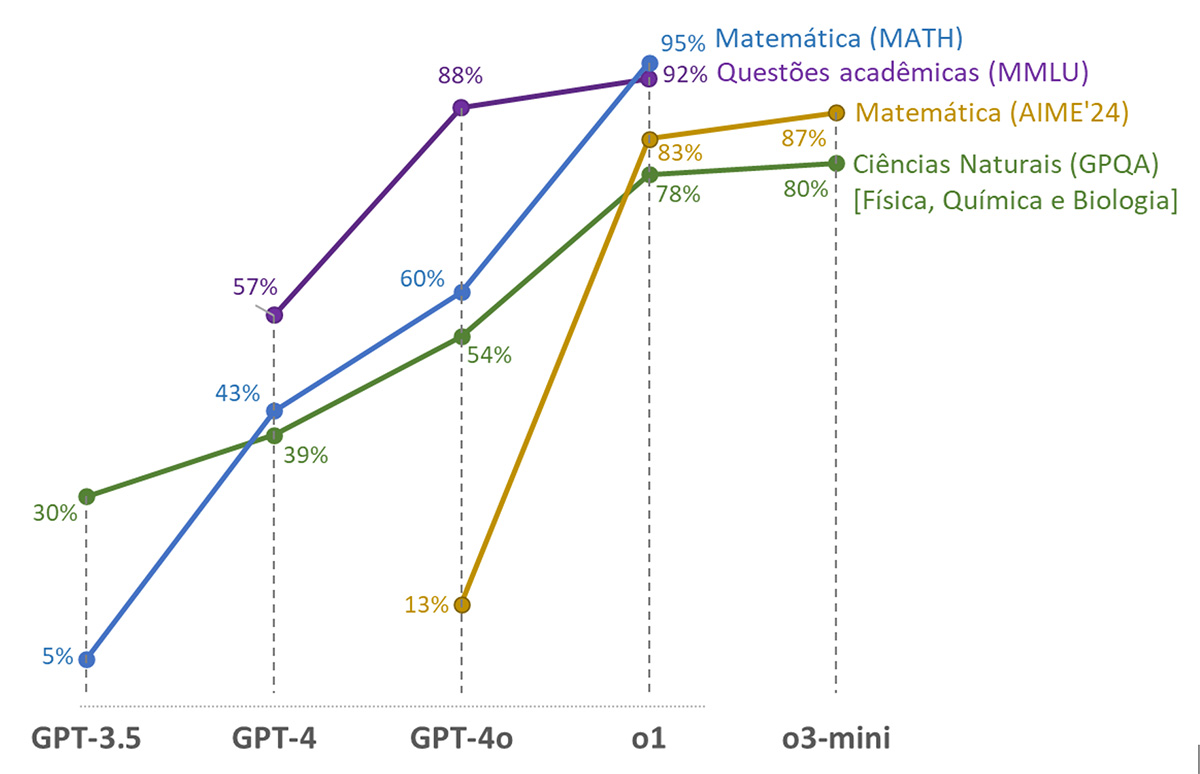
Fonte: dos autores, com base nos dados: OpenAI (2023d; 2024c; 2024f; 2025d; 2025e); Yue et al. (2024); Rein et al. (2023); Hendrycks et al. (2021).
A utilidade dos modelos de linguagem para a área da Matemática reside no fato de conseguirem dar explicações, detalhar estratégias de resolução, apresentar um passo a passo para a resolução de um problema, justificar uma resposta, tirar dúvidas. Nesse sentido, a tecnologia generativa complementa outras tecnologias que garantem precisão nos cálculos e fornecem visualizações gráficas precisas e interativas.
Com essas avaliações, queremos ilustrar que os modelos de linguagem vêm sendo aperfeiçoados a cada ano: aumentam a quantidade de informações armazenadas (parâmetros), processam mais dados durante o treinamento, aprimoram as técnicas utilizadas e implementam novas abordagens de processamento da informação (como a Cadeia de Pensamento), entre outros avanços.
Os testes de desempenho utilizados aqui para demonstrar a evolução das sucessivas versões do GPT também servem para comparar o desempenho entre os modelos concorrentes. Nos dois primeiros anos após o lançamento do ChatGPT, além da OpenAI, empresas como o Google (modelo Gemini), a Anthropic (modelo Claude), a xAI (modelo Grok) e a Meta (modelo LLaMa) passaram a disputar uma corrida para desenvolver o modelo de linguagem mais poderoso, capaz de acertar mais questões nos testes de desempenho, resolver problemas mais complexos, alucinar menos e promover a melhor experiência para as/os usuárias/os. Em 2025, o mundo foi surpreendido pelo lançamento de modelos desenvolvidos por empresas chinesas, como o DeepSeek-v3 (DeepSeek, 2025) e o Qwen-2.5 (Qwen, 2025), que apresentaram desempenho superior, em alguns testes, em relação aos modelos gratuitos do GPT. A corrida pela liderança em IA generativa tornou-se uma competição global, o que tem impulsionado a produção de modelos cada vez mais avançados e úteis.
Apesar dos avanços frenéticos que tornam a IA generativa cada vez mais relevante para a educação, devemos também reconhecer suas limitações. Por exemplo, sabemos que o modelo GPT-3.5 havia sido treinado com textos da Wikipédia, de livros, fóruns e blogs, mas não com artigos de revistas científicas. Por isso, ele não se equiparava aos conhecimentos de uma pessoa doutora em uma área específica. Perguntas que exigiam um conhecimento muito avançado nem sempre eram bem respondidas pelo GPT-3.5.
Às vezes, a IA generativa gera conteúdo com informações erradas, mas, por produzir um texto bem escrito, pode parecer que está mentindo. Entretanto, a IA generativa não tem intencionalidade: não quer nos enganar ou mentir. Essa tecnologia não compreende a semântica do texto e não tem como julgar se o texto gerado contém informação verdadeira ou falsa. Para lidar com essa limitação, pesquisadoras/es e desenvolvedoras/es têm investigado algumas soluções. Por exemplo, no Gemini, após a geração de uma resposta, pode ser feita a checagem da informação por meio de uma busca na internet por conteúdos relacionados a cada frase gerada. Outra estratégia é criar modelos maiores e treinados com mais textos sobre todos os assuntos, o que potencialmente reduz a ocorrência de alucinações, embora não as elimine por completo.
A possibilidade de alucinação aumenta se o modelo tiver sido treinado com pouco conteúdo relacionado ao prompt digitado pela/o usuária/o. Por exemplo, o GPT-3.5 havia processado poucos textos em português e, portanto, possuía informações limitadas sobre nossa história, cultura, valores, costumes e crenças, o que aumentava a chance de alucinação em perguntas relacionadas ao Brasil. Quando um modelo é treinado com pouca informação sobre determinado assunto, pode acabar reproduzindo o mesmo conteúdo processado, seja por meio de paráfrase ou transcrição literal, o que é considerado plágio:
Pesquisadores da Universidade do Estado da Pensilvânia (Penn State), nos Estados Unidos, investigaram até que ponto modelos de linguagem natural como o ChatGPT, que usam inteligência artificial para formular uma prosa realista e articulada em resposta a perguntas de usuários, conseguem gerar conteúdo que não se caracterize como plágio. Isso porque esses sistemas processam, memorizam e reproduzem informações preexistentes, baseadas em gigantescos volumes de dados disponíveis na internet, tais como livros, artigos científicos, páginas da Wikipédia e notícias.
O grupo analisou 210 mil textos gerados pelo programa GPT-2, da startup OpenAI, criadora do ChatGPT, em busca de indícios de três diferentes tipos de plágio: a transcrição literal, obtida copiando e colando trechos; a paráfrase, que troca palavras por sinônimos a fim de obter resultados ligeiramente diferentes; e o uso de uma ideia elaborada por outra pessoa sem mencionar sua autoria, mesmo que formulada de maneira diferente.
A conclusão do estudo foi de que todos os três tipos de cópia estão presentes. (Marques, 2023)
As informações geradas pelo modelo de linguagem também ficam desatualizadas em função do momento em que foi realizado seu treinamento. Por exemplo, em 2024, perguntamos ao GPT-3.5: “Quem é o presidente do Brasil?”, e ele respondeu: “Atualmente, o presidente do Brasil é Jair Bolsonaro”[3]. Para lidar com essa limitação, muitas tecnologias generativas passaram a recuperar informações da internet em tempo real para apoiar a geração de respostas com dados atualizados.
É comum que pessoas façam perguntas à IA sobre seu funcionamento e sua natureza: potencialidades, limitações, implicações e características técnicas. Contudo, essa tecnologia não possui consciência de si mesma, o que a impede de refletir sobre sua própria existência, seu funcionamento e suas técnicas. Apesar disso, muitas pessoas insistem em fazer perguntas como se ela possuísse autoconhecimento[4].
É importante conhecer as limitações da IA generativa para que possamos dar sentido às suas respostas, especialmente quando são equivocadas ou superficiais. No entanto, essas limitações não devem nos levar à conclusão de que a IA generativa é inútil. Mostramos que mesmo as versões iniciais dos modelos GPT já apresentavam boa capacidade de interpretação de textos e de raciocínio sobre conteúdos científico-educacionais (embora com desempenho insatisfatório em Matemática). Mostramos, também, que os modelos continuam sendo aprimorados em uma corrida incessante para desenvolver versões cada vez mais eficazes. Com essa discussão, queremos que até as pessoas mais céticas ou decepcionadas, como o pai do primeiro autor, tenham certeza de que os modelos de IA generativa são muito relevantes para os processos educacionais e se tornarão cada vez mais úteis. Esse é o ponto de partida para as reflexões que tecemos neste livro.
_______________
[2] No Enem 2022, 3,5 milhões de pessoas se inscreveram, mas somente 2,3 milhões fizeram as quatro provas (33% das pessoas não fizeram as provas). No Enem 2023, 3,9 milhões de pessoas se inscreveram, mas somente 2,7 milhões fizeram as quatro provas do Enem (32% das pessoas deixaram de fazer as provas daquele Enem). ). No Enem 2024, 4,3 milhões de pessoas se inscreveram, mas somente 3,0 milhões fizeram as quatro provas do Enem (31% das pessoas deixaram de fazer as provas daquele Enem).
[3] Disponível em: https://chatgpt.com/share/7c7ea738-a3f7-4fe1-9da4-4fe7645d146f
[4] Um modelo pode vir a gerar informações corretas sobre si mesmo se ele tiver sido treinado com esse tipo de conteúdo.