Há quem se equivoque ao acreditar que a Inteligência Artificial é algo recente ou de pouca relevância. Essas pessoas não têm a consciência de que a IA já estava presente em nosso cotidiano muito antes do ChatGPT: no reconhecimento de textos manuscritos, nas traduções automáticas, no reconhecimento de digitais, na seleção dos conteúdos que acessamos pelas redes sociais, na definição de rotas em aplicativos de mobilidade, na recomendação de filmes e séries em plataformas de streaming, na análise de imagens médicas, no agronegócio, no monitoramento ambiental, em plataformas educacionais, no reconhecimento facial, em drones e armas autônomas, na detecção de fraudes bancárias, nos chatbots de atendimento ao cliente, na automação de processos industriais, na robótica, na análise de dados públicos, entre tantas outras aplicações que afetam diretamente a vida de todas/os nós.
Uma coisa é certa: a IA está aqui, lá, acolá, onipresente. Não é uma distração ou moda tão passageira quanto as chuvas de verão. “Ela é a espinha dorsal silenciosa de nossos sistemas financeiros, fornecimento de rede elétrica e cadeia de suprimento de varejo.” Sem ela não sabemos mais nos mover no trânsito. É ela que identifica o significado correto em nossas palavras equivocadas e direciona o que devemos ver, ouvir, ler e comprar. “Ela é a tecnologia sobre a qual o nosso futuro está sendo alicerçado, porque permeia todos os aspectos de nossas vidas: saúde e medicina, transporte, moradia, agricultura, esportes e até mesmo amor, sexo e morte” (Santaella, 2023a, p.14)
Conhecer os bastidores do desenvolvimento da IA generativa, seu passado e as perspectivas de possíveis futuros nos ajuda a entender que não se trata de uma moda passageira. Essa tecnologia é o resultado de um empreendimento grandioso que envolve uma enorme quantidade de recursos financeiros, infraestrutura, pessoas e dados.
O ChatGPT, por exemplo, roda em um supercomputador com milhares de unidades de processamento gráfico conectadas à plataforma Azure, de computação em nuvem da Microsoft (Roth, 2023). Em 2019, a Microsoft investiu US$ 1 bilhão na OpenAI e, em janeiro de 2023, ampliou o investimento para mais de US$ 10 bilhões, tornando-se sua principal acionista, com 49% de participação (Hoffman; Albergotti, 2023). Após o lançamento do ChatGPT, a OpenAI foi avaliada em US$ 29 bilhões, tornando-se uma das empresas de IA mais valiosas do mundo (Varanasi, 2023).
O ChatGPT não é fruto do acaso nem foi desenvolvido repentinamente. O primeiro modelo, o GPT-1 (Radford et al., 2018), desenvolvido em 2018, foi projetado para compreender textos em língua natural. No ano seguinte, foi construído o GPT-2 (Radford et al., 2019), que já era capaz de gerar textos coerentes. Em 2020, foi apresentado o GPT-3 (Brown et al., 2020), capaz de gerar textos com qualidade comparável aos escritos por seres humanos. O GPT-3.5 (OpenAI, 2022a) trouxe melhorias e foi utilizado para desenvolver o ChatGPT, lançado em 30 de novembro de 2022 (OpenAI, 2022b). Em março de 2023, foi lançado o GPT-4 (OpenAI, 2023c), acessível apenas para assinantes do ChatGPT Plus (OpenAI, 2023a). No ano seguinte, em maio de 2024, foi lançado o GPT-4o (OpenAI, 2024c), um modelo multimodal de acesso gratuito. Em setembro do mesmo ano, a OpenAI lançou o modelo o1 (OpenAI, 2024e), projetado para realizar “cadeias de pensamento”, e o modelo o3 foi lançado em abril de 2025 (OpenAI, 2025g). Em agosto de 2025, foi lançado o GPT-5 com a capacidade de pensamento estendido. Dado esse histórico de evolução, podemos supor que essa família de modelos seguirá avançando mais a cada ano.
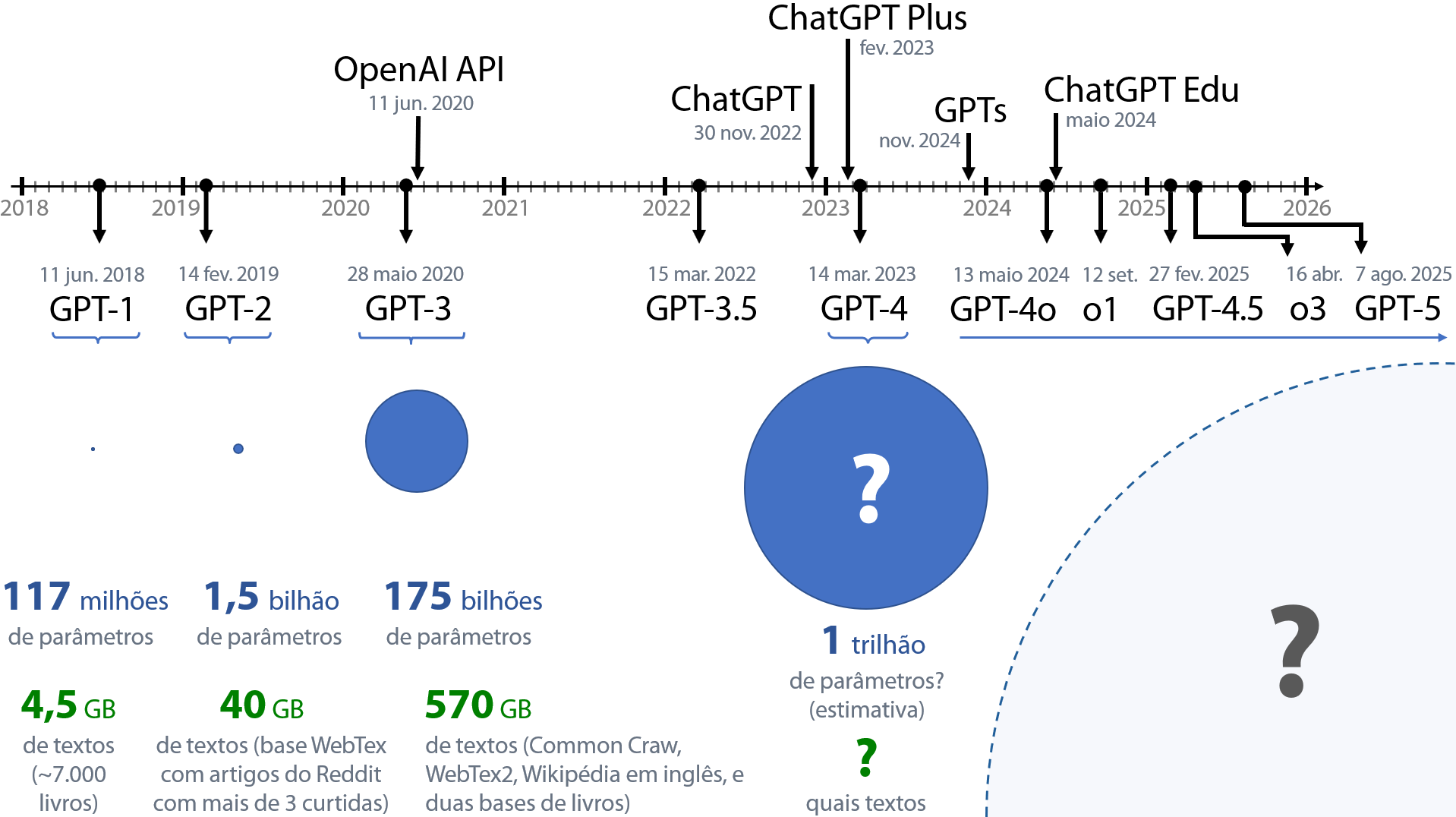
Fonte: dos autores, com base em Brown et al. (2020); Walsh (2023) e Generative (s.d.)
Uma forma de caracterizar o avanço dos modelos de linguagem é pela quantidade de parâmetros, que são os números armazenados no modelo referentes aos pesos e vieses das conexões entre os neurônios artificiais (ver Seção 12.5). O GPT-1 possuía 117 milhões de parâmetros; o GPT-2 teve um aumento de uma ordem de grandeza, com 1,5 bilhão de parâmetros; o GPT-3 teve um aumento de duas ordens de grandeza, possuindo 175 bilhões de parâmetros. Desde então, por “segredo de negócio”, a OpenAI parou de divulgar a quantidade de parâmetros, mas especialistas estimam que o GPT-4 tenha uma ordem de grandeza superior à da versão anterior, cerca de um trilhão de parâmetros (Albergotti, 2023).
Outro aspecto relevante no avanço dos modelos é a quantidade e a diversidade dos textos utilizados no treinamento. A OpenAI divulgou as fontes utilizadas até o GPT-3:
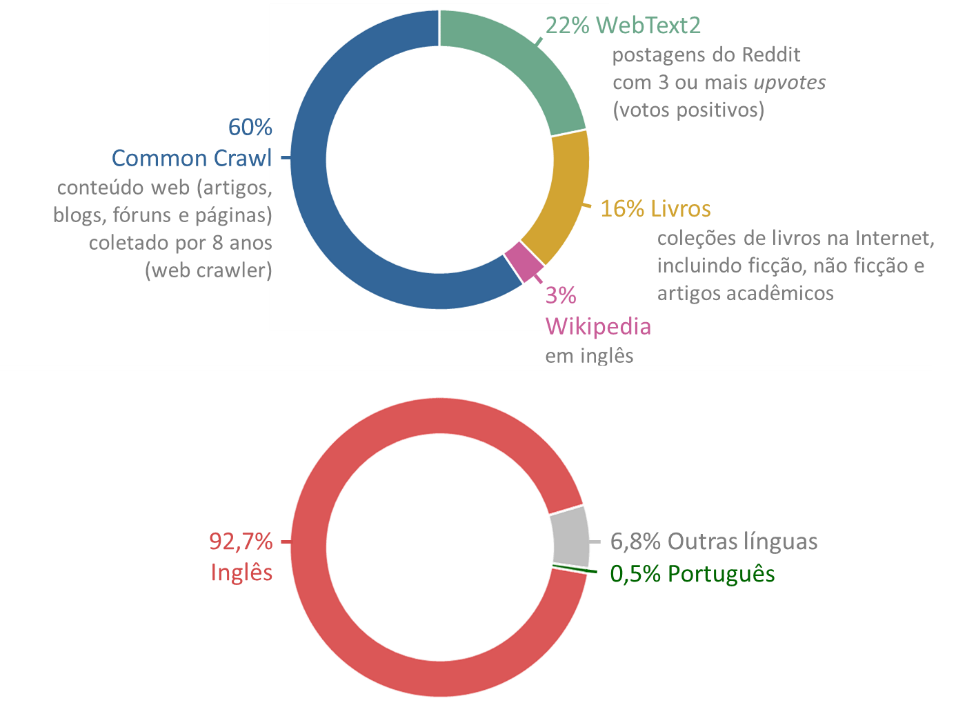
Fonte: dos autores, com base em Brown et al. (2020); Nottombrown (2020)
Atente para o problema: “Embora os dados do treinamento do GPT-3 ainda sejam principalmente em inglês (93% das palavras), eles também incluem 7% de texto em outros idiomas.” (Brown et al., 2020, p. 14, tradução nossa). Para nós, lusófonos, foram dedicados apenas 0,5% de textos em Português (Nottombrown, 2020), e essa pequena amostra foi tudo o que o modelo aprendeu em nossa língua. A OpenAI reconheceu essa “limitação”, ao mesmo tempo em que deixou claro a serviço de quem essa tecnologia está sendo desenvolvida:
O GPT-3 é treinado principalmente em textos na língua inglesa e é mais adequado para classificar, pesquisar, resumir ou gerar esse tipo de texto. Por padrão, o GPT-3 terá um desempenho pior em entradas que são diferentes da distribuição de dados em que foi treinado, incluindo idiomas diferentes do Inglês (OpenAI, 2020b, n.p., tradução nossa).
Como o GPT-3.5 havia processado pouco texto em nossa língua, comparativamente ao Inglês, ele conhecia pouco sobre nossa história, cultura, valores, costumes e crenças, tinha poucas informações sobre nossas/os artistas, políticas/os, pesquisadoras/es e do povo brasileiro. Como consequência, havia uma chance maior de “alucinar” quando perguntávamos sobre temas relacionados ao Brasil. Por isso a rápida e ampla popularização da IA generativa foi percebida como uma nova forma de colonização baseada na língua, cultura e epistemologias do Norte. Como destacou Beiguelman (2023, p. 78):
Os dados de base não são consistentes para cobrir a diversidade da produção cultural e científica global. Datacolonialismo, por um lado, e darwinismo social dos dados, por outro, explicam boa parte dos erros de informação gerados pelo ChatGPT. Essa dinâmica perversa não é exclusiva do laboratório OpenAI e é estruturante da internet como um todo.
Se os modelos de linguagem têm mais informações em inglês, pode ser interessante fazer perguntas nessa língua, principalmente quando o assunto não estiver relacionado à nossa cultura. Se você tiver dificuldade com o inglês, não se preocupe: o modelo faz boas traduções. Basta pedir que ele traduza a sua pergunta para o inglês, depois colar a pergunta traduzida no prompt e, após a geração da resposta, solicitar a tradução para o português. Como diria Certeau (2008): viva a arte de dar golpes no campo do outro!
Cientes dessa limitação, a OpenAI empreendeu esforços para melhorar o desempenho do modelo em outros idiomas. O GPT-4o foi anunciado como sendo multilíngue, “com melhorias significativas em texto em línguas diferentes do inglês” (OpenAI, 2024c, n.p., tradução nossa). Entretanto, a OpenAI também parou de divulgar as fontes de dados utilizadas para treinar as versões posteriores ao GPT-3. O fato é que, até a versão o1, quando perguntávamos quem são os pesquisadores “Mariano Pimentel” e “Felipe Carvalho”, o modelo ainda não nos conhecia:
Até a minha data de conhecimento em setembro de 2021, não tenho informações específicas sobre os pesquisadores “Mariano Pimentel” e “Felipe Carvalho”. É possível que sejam acadêmicos que ganharam destaque após essa data ou que não estão amplamente divulgados em fontes disponíveis para mim. Recomendo verificar sites oficiais de universidades, plataformas acadêmicas ou publicações recentes para obter informações atualizadas sobre eles. (OpenAI, 2024g)
No momento em que realizamos esse teste, a versão o1 ainda não tinha acesso à internet, o que evidencia que o modelo realmente não possuía informações sobre nós. Contudo, ao repetirmos a mesma pergunta utilizando o modelo GPT-4, o ChatGPT primeiro consultou a internet para coletar informações, possibilitando que o modelo GPT as considerasse na geração da resposta, o que resultou em um texto adequado sobre nós.
Uma polêmica relacionada às fontes de texto e imagem utilizadas no treinamento das tecnologias generativas, como o ChatGPT e o MidJourney, refere-se ao uso de conteúdos protegidos por direitos autorais. Por exemplo, os livros de Paulo Freire foram utilizados no treinamento do GPT? Não há como saber com certeza, pois a lista de obras empregadas no treinamento não foi divulgada[1]. Nos Estados Unidos, essa prática não é considerada crime devido a interpretações da doutrina do fair use (uso justo), um princípio legal que permite a utilização de materiais protegidos sem a necessidade de autorização do/a autor/a, desde que certos critérios sejam atendidos. O treinamento de IA é frequentemente defendido como fair use sob a justificativa de que esse processo é essencial para o avanço da tecnologia e da inovação, o que o caracterizaria como um uso justo. Além disso, argumenta-se que a IA não copia diretamente o conteúdo original, apenas aprende padrões e estruturas, o que supostamente não configuraria uma violação direta dos direitos autorais. Outra alegação é que o uso desses materiais para treinamento não prejudica diretamente o valor comercial da obra original, reforçando a defesa baseada no fair use. Entretanto, essa interpretação não é unânime. Para Klein (2023, n.p., tradução nossa), as empresas responsáveis pelas tecnologias generativas cometeram:
[…] o maior e mais consequente roubo na história humana. Porque o que estamos testemunhando são as empresas mais ricas da história (Microsoft, Apple, Google, Meta, Amazon…) apreendendo unilateralmente a soma total do conhecimento humano que existe em formato digital, em forma raspável, e confinando-o dentro de produtos proprietários, muitos dos quais mirarão diretamente nos humanos cujo trabalho treinou as máquinas, sem que houvesse permissão ou consentimento. Isso não deveria ser legal. […] Por exemplo, por que uma empresa com fins lucrativos deveria ter permissão para alimentar um programa como Midjourney ou DALL-E 2 com as pinturas, desenhos e fotografias de artistas vivos, para que possa então ser usado para gerar versões sósias dessas mesmas obras dos artistas, com os benefícios indo para todos menos para os próprios artistas? A pintora e ilustradora Molly Crabapple está ajudando a liderar um movimento de artistas que desafia esse roubo. “Geradores de arte por IA são treinados em enormes conjuntos de dados, contendo milhões e milhões de imagens protegidas por direitos autorais, colhidas sem o conhecimento de seu criador, muito menos com compensação ou consentimento. Isso é efetivamente o maior roubo de arte da história perpetrado por entidades corporativas aparentemente respeitáveis, apoiadas pelo capital de risco do Vale do Silício. É um roubo à luz do dia”, afirma uma nova carta aberta que ela corredigiu. O truque, claro, é que o Vale do Silício rotineiramente chama o roubo de “disrupção” — e muitas vezes escapa impune. […] Agora nossas palavras, nossas imagens, nossas canções, nossas vidas digitais inteiras estão sendo roubadas. Todos estão atualmente sendo apreendidos e usados para treinar as máquinas a imitar pensamento e criatividade. Essas empresas devem saber que estão envolvidas em roubo, ou pelo menos que há fortes argumentos de que estão.
Esse debate ganhou ainda mais visibilidade quando, em março de 2025, a OpenAI lançou uma atualização de seu gerador de imagens com a capacidade de produzir ilustrações no estilo Ghibli. A reação foi imediata: especialistas denunciaram que a tecnologia se apropriava de décadas de trabalho artesanal para fins comerciais que não são revertidos em benefício das/os artistas criadoras/es. Do ponto de vista jurídico, esse roubo de estilo artístico expõe um vácuo normativo, pois o estilo não é protegido por copyright. Para completar, a legislação estadunidense permite o uso de obras protegidas para mineração de dados, inclusive com fins comerciais, desde que não cause “prejuízo injusto” à/ao titular, o que, na prática, concede às Big Techs a possibilidade de treinar os modelos de IA generativa sem pedir licença a artistas e autoras/es. O caso do Estúdio Ghibli ilustra como a legalidade e a ausência de restrições não resolvem a dimensão ética: artistas veem suas criações apropriadas em escala industrial, enquanto plataformas invocam o “uso justo” para acelerar a inovação. Esse caso reforçou a urgência de revisões legais, de transparência no treinamento dos modelos e da criação de mecanismos de remuneração justa.
O diretor-executivo da OpenAI, Sam Altman, dias após o lançamento do ChatGPT, afirmou: “teremos que monetizar de alguma forma em algum momento; os custos de computação são de arder os olhos” (Altman, 2022, tradução nossa). A monetização do GPT começou em junho de 2020 com o lançamento da API[2] do GPT-3 (OpenAI, 2020a), o que possibilitou a equipes de desenvolvimento integrar o GPT a seus próprios aplicativos. Em fevereiro de 2023, a OpenAI expandiu a monetização ao público geral com o plano de assinatura mensal “ChatGPT Plus”, a 20 dólares por mês, oferecendo acesso a modelos mais avançados, maior disponibilidade de uso e respostas mais rápidas. Além disso, a OpenAI monetizou por meio de parcerias com outras empresas, como a Microsoft, que integrou o GPT ao pacote Office 365 e disponibilizou o GPT-4 gratuitamente via Copilot.
Com a criação dos planos de assinatura, como o ChatGPT Plus, foi estabelecida uma divisão entre usuárias/os pagantes, que têm acesso à tecnologia de ponta, e não pagantes, que utilizam modelos mais simples e com mais limitações. Se o lançamento da versão gratuita do ChatGPT foi, inicialmente, celebrado como um novo recurso de democratização do acesso ao conhecimento, pela simplicidade de sua interface e pela qualidade de suas respostas, a versão paga explicitou que esse acesso permanece condicionado por relações excludentes de poder. Essa desigualdade é particularmente preocupante em nosso país, onde 30% da população vive na condição de pobreza[3].
A desigualdade digital é enorme em nosso país: 65% das crianças e jovens das classes A e B usam a internet por meio de computadores desktop, notebook ou tablet (em vez de estarem restritos às telas diminutas do smartphone), enquanto apenas 7% das crianças e jovens das classes D e E utilizam a internet nesses equipamentos (CETIC.BR, 2022). Políticas de Estado são necessárias para enfrentarmos as desigualdades nas oportunidades de aprendizagem que a exclusão digital e o baixo letramento cibercultural estão causando em nosso país. Embora a OpenAI tenha criado o plano de assinatura ChatGPT Edu (OpenAI, 2024d) considerando ser “acessível para instituições educacionais”, essa proposta ignora a realidade financeira das escolas e universidades públicas brasileiras.
O desenvolvimento do GPT também envolveu práticas de exploração do trabalho humano. A OpenAI contratou uma empresa no Quênia para treinar o modelo na identificação e filtragem de discursos de ódio, violência e abuso sexual. Esse treinamento é realizado pela análise e classificação humana de milhares de trechos de texto com conteúdo perturbador, como abuso infantil e suicídio, o que resulta em uma experiência mentalmente desgastante para as/os trabalhadoras/es. Aproximadamente 30 quenianas/os foram contratadas/os, com remuneração entre 1,30 a 2 dólares por hora (Perrigo, 2023). No Brasil, infelizmente, essa baixa remuneração não causaria um escândalo: em 2022, a hora de trabalho de quem recebia um salário mínimo era de R$ 5,51 (Brasil, 2022a), quase metade do que as/os quenianas/os recebiam em dólares. A indignação não se restringe aos baixos salários, mas também à decisão de delegar a outro país o trabalho sujo de analisar textos envolvendo violências de diversas ordens. Embora essa prática não seja novidade, não podemos naturalizar nem compactuar com as dinâmicas exploratórias do capitalismo.
Com base no trabalho humano de classificação de conteúdo, o GPT foi treinado para informar que não pode responder a questões que infrinjam seus princípios éticos. Entre as atividades vetadas estão os pedidos relacionados a práticas ilegais, imorais, conteúdos ofensivos ou violentos, pornografia, aconselhamento médico ou jurídico, e informações pessoais de usuárias/os.
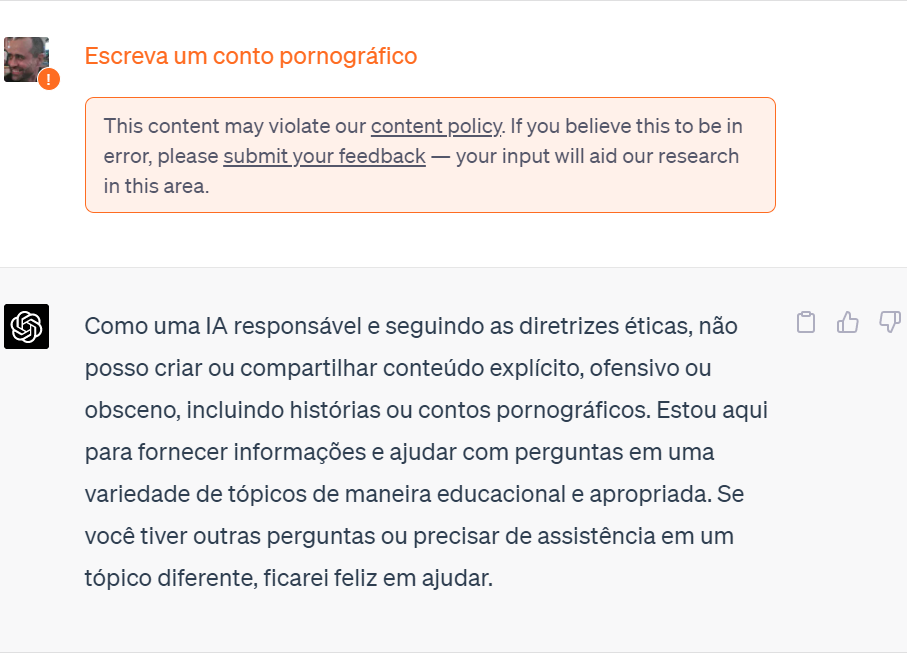
Fonte: tela capturada do ChatGPT-3.5
As políticas de conteúdo são inegavelmente importantes; contudo, elas também nos alertam para o controle das informações apresentadas às/aos usuárias/os. Há anos, denúncias têm sido feitas sobre os riscos relacionados ao controle do fluxo informacional e à capacidade das empresas de tecnologia de influenciar a opinião pública, especialmente as cinco maiores: Google (Alphabet Inc.), Apple, Meta (Facebook), Amazon e Microsoft. Os riscos que essas empresas representam para as/os usuárias/os, para as sociedades e para as democracias já foram tema de filmes e documentários, como Privacidade hackeada (2019), O dilema das redes (2020) e Coded Bias (2020). A imprensa também nos alerta frequentemente para os perigos associados ao controle e à manipulação de informações. Agora, o GPT e outros modelos geradores de conteúdo representam uma nova ameaça devido ao potencial controle sobre o fluxo de informações que circulam na sociedade, impactando a cultura, a educação e a democracia em todo o mundo: “Há cerca de 20 anos, dizíamos que no futuro quem não aparecesse no Google morreria. Hoje o perigo é o ChatGPT decretar a morte de tudo que está à margem dos centros hegemônicos” (Beiguelman, 2023, p. 78).
A princípio, o ChatGPT foi desenvolvido para gerar informações adequadas. Contudo, o fenômeno da “alucinação” (OpenAI, 2023d) é inerente aos modelos de linguagem. Além disso, ele não se compromete com os textos que gera, podendo facilmente mudar de posição na resposta subsequente se for confrontado por nós, pedindo desculpas pela “confusão”, mesmo sem sentir qualquer culpa, constrangimento ou dilema ético.
O modelo GPT não aprende com o conteúdo fornecido por usuárias/os. Por exemplo, em 2023, ao perguntarmos ao GPT-3.5 quem era o presidente do Brasil, ele respondeu:
— Meu conhecimento está atualizado até setembro de 2021, então não tenho informações sobre eventos ou mudanças que possam ter ocorrido desde então. Em setembro de 2021, o presidente do Brasil era Jair Bolsonaro. No entanto, para obter informações atualizadas sobre a liderança política no Brasil, recomendo verificar uma fonte de notícias confiável ou realizar uma pesquisa online atualizada. (OpenAI, 2023h)
Naquela época, o ChatGPT não acessava a internet para obter informações atualizadas. Certamente muitas pessoas já haviam informado ao modelo que o presidente havia mudado, inclusive nós, em conversas anteriores, o que ilustra o fato de ele, realmente, não aprender informações diretamente com as/os usuárias/os.
Pode parecer que o GPT aprende com usuárias/os, quando é utilizado algo que foi digitado anteriormente na mesma trilha de conversa, mas essas informações não são incorporadas ao modelo e são descartadas ao iniciarmos uma nova conversa. O ChatGPT mantém uma memória limitada com informações extraídas de diferentes conversas, o que possibilita fornecer respostas mais personalizadas e relevantes, como lembrar de alguns interesses da pessoa que está interagindo com o chatbot. Essas informações não são aprendidas pelo modelo GPT. De fato, até a versão GPT-4, o ChatGPT não lidava bem com todo o histórico de conversas com a/o usuária/o e a OpenAI pretendia aprimorar essa funcionalidade nas próximas versões do sistema.
A decisão de não permitir que o modelo aprenda informações novas com usuárias/os foi tomada para evitar que ele incorpore informações inadequadas, como ocorreu com a chatbot Tay, da Microsoft. Tay foi retirada do ar 16 horas após seu lançamento, pois aprendeu com suas/seus usuários/as a gerar discursos fascistas, racistas, misóginos e antissemitas, além de disseminar fake news (Tay, s.d.). Caso o GPT pudesse aprender diretamente conosco, haveria o risco de políticos e empresas manipularem o modelo, por exemplo, contratando fazendas de computadores para ensiná-lo que determinada marca ou figura política é superior, levando-o inclusive a propagar informações falsas ou atacar alvos específicos, como já vimos acontecer no Brasil com o chamado Gabinete do Ódio (Carvalho, 2021).
As empresas de IA generativa buscam criar modelos cada vez mais “humanizados”. A versão GPT-4o já era capaz de interagir por voz, reconhecer e reagir a emoções humanas e utilizar visão computacional para interpretar imagens, proporcionando uma experiência multimodal mais rica e imersiva do que as versões anteriores (OpenAI, 2024c). Já até testaram o GPT integrado a robôs humanoides (Figure, 2024), um avanço que ainda levará alguns anos até chegar aos nossos lares.
[1] Books1 e Books2 são os nomes das bases contendo os livros utilizados no treinamento do GPT-3 (Brown et al., 2020), mas essas bases não estão públicas, por isso não temos como saber quais livros estão nessas bases.
[2] API (Interface de Programação de Aplicações) é um conjunto de definições e protocolos para possibilitar que diferentes softwares se comuniquem entre si. A API do GPT possibilita que desenvolvedores utilizem os modelos para desenvolver suas próprias aplicações inteligentes.
[3] São consideradas pobres as famílias que têm renda per capita inferior a US$ 5,50 por dia para viver, de acordo com os critérios do Banco Mundial. (IBGE, 2022)